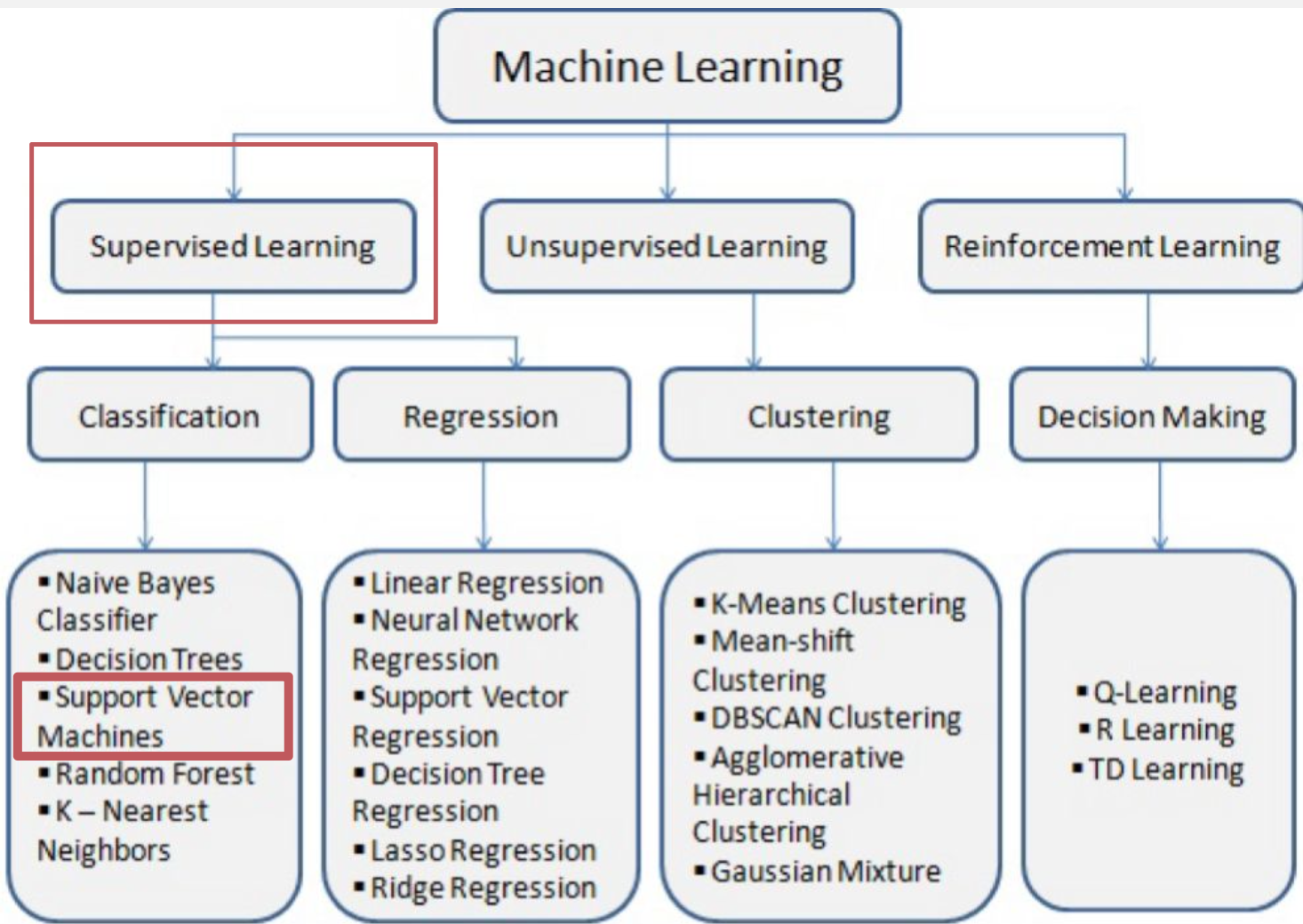
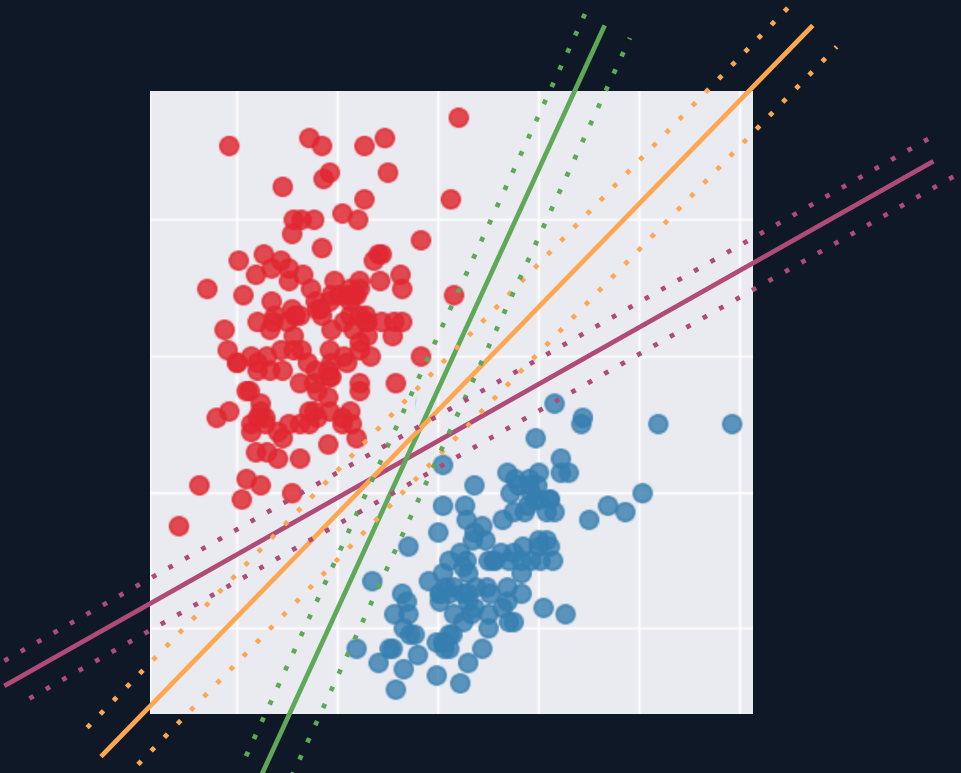
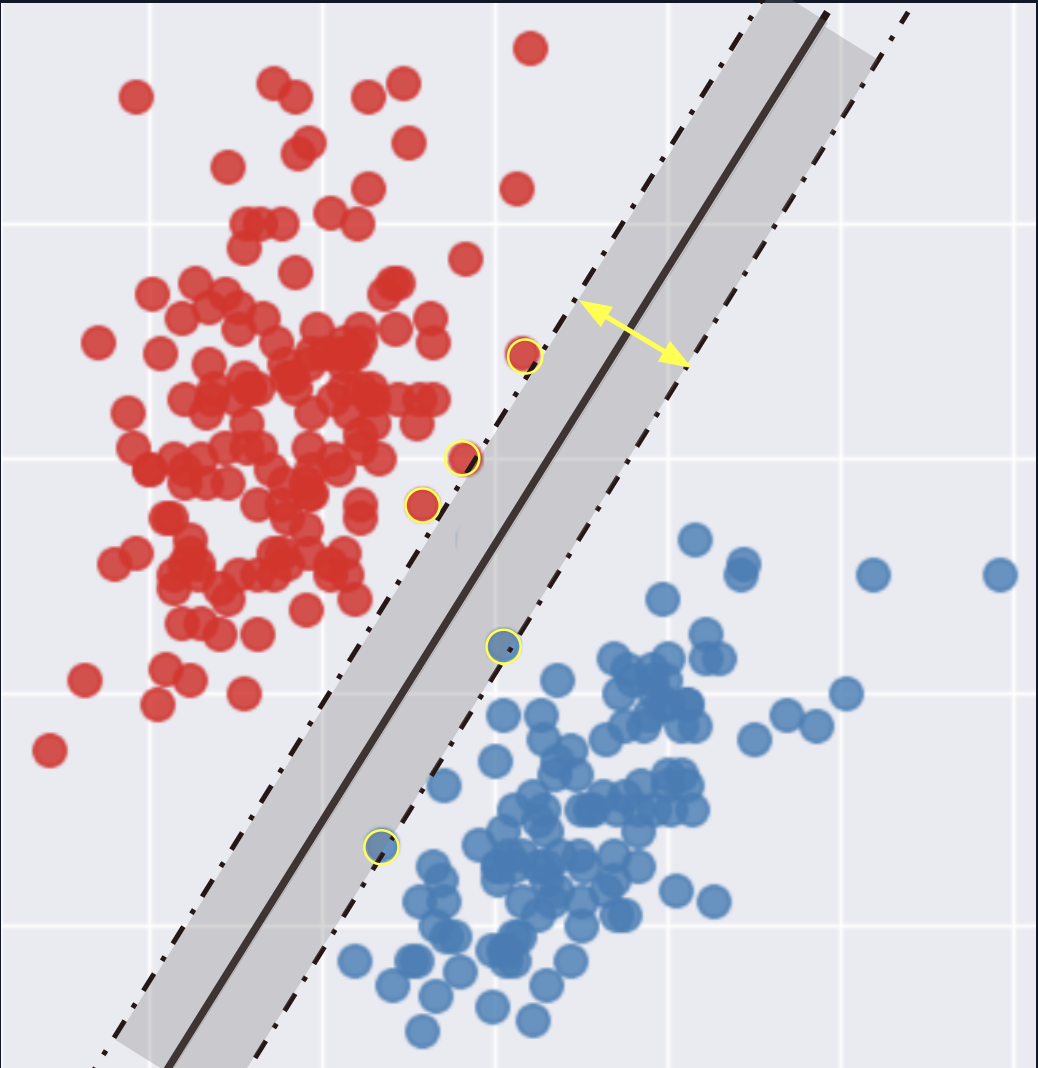
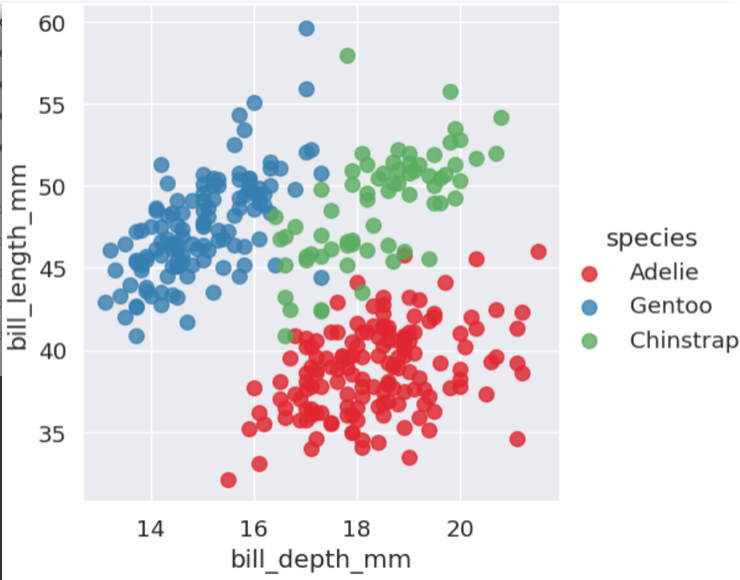
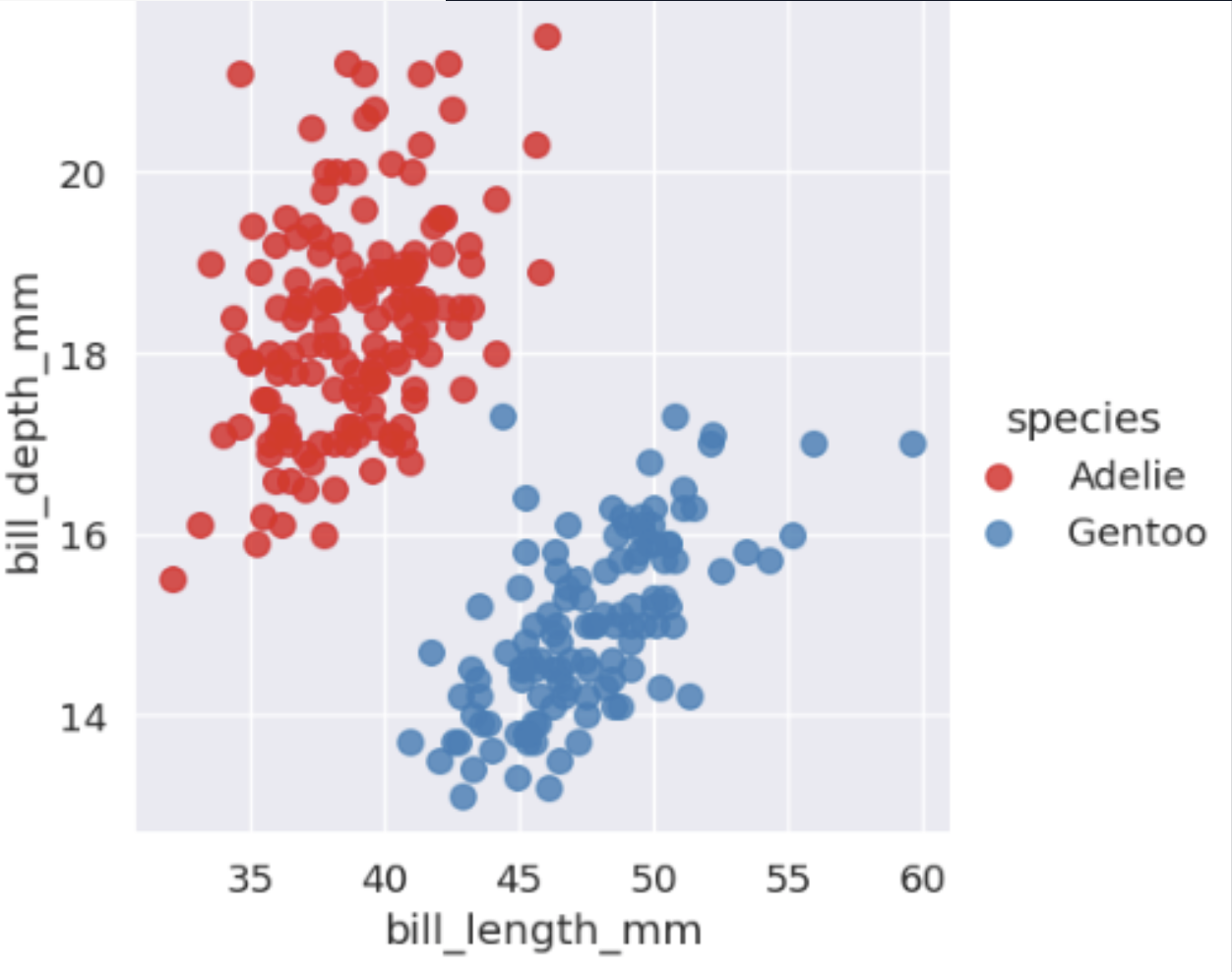
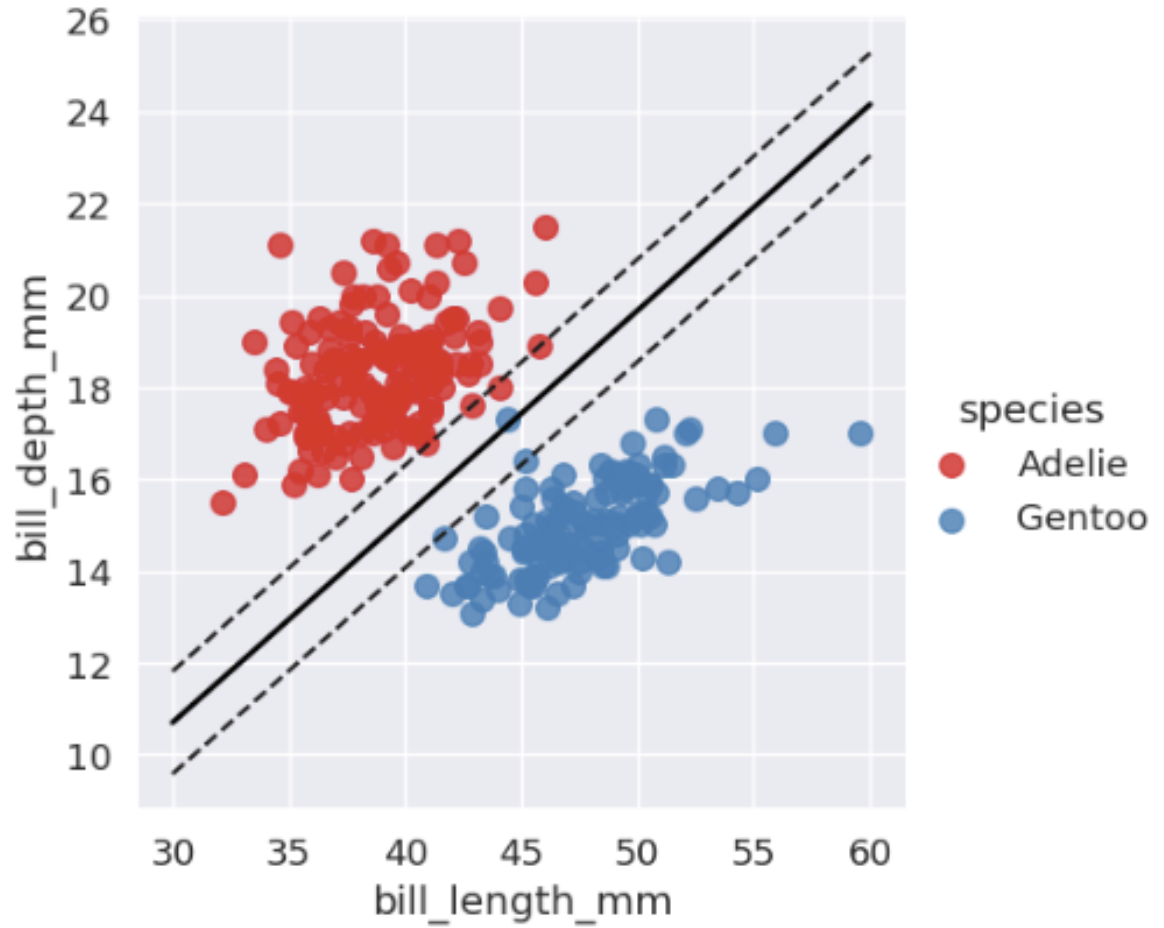
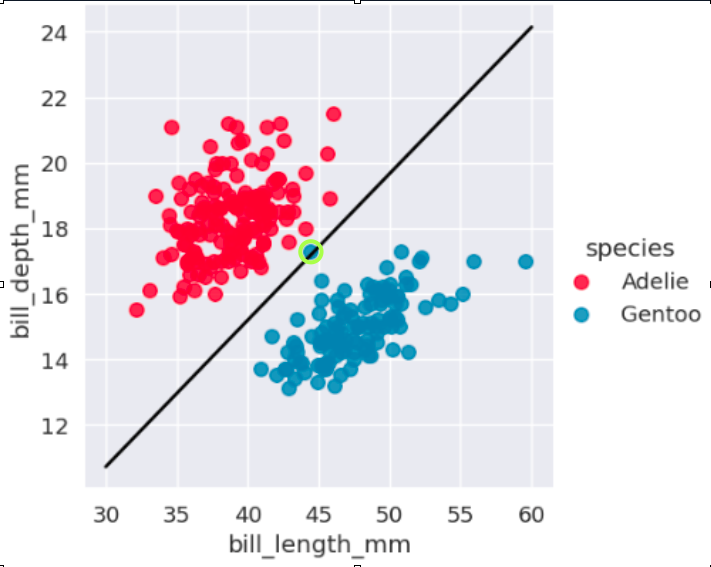
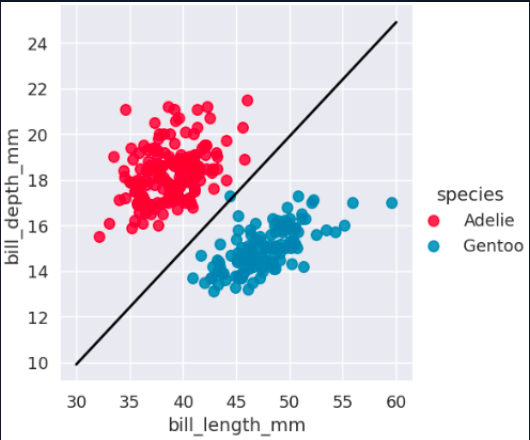
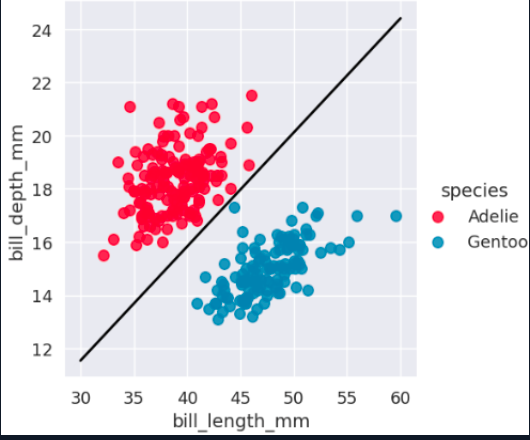
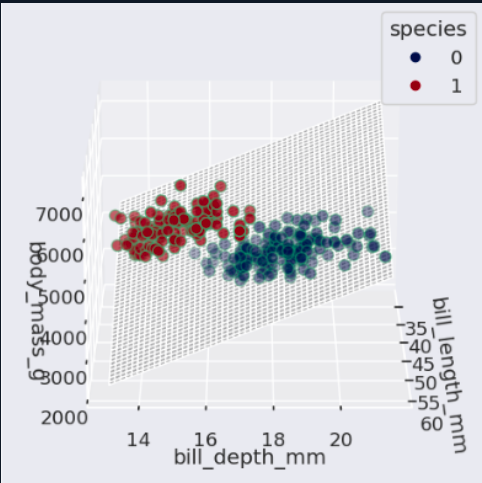
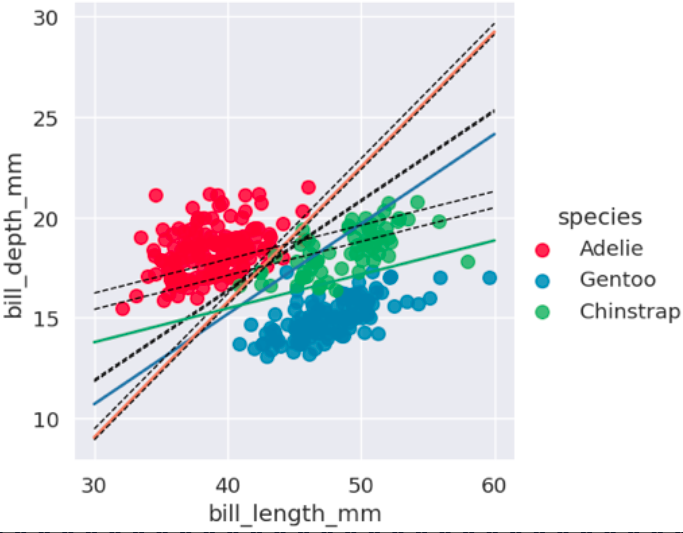
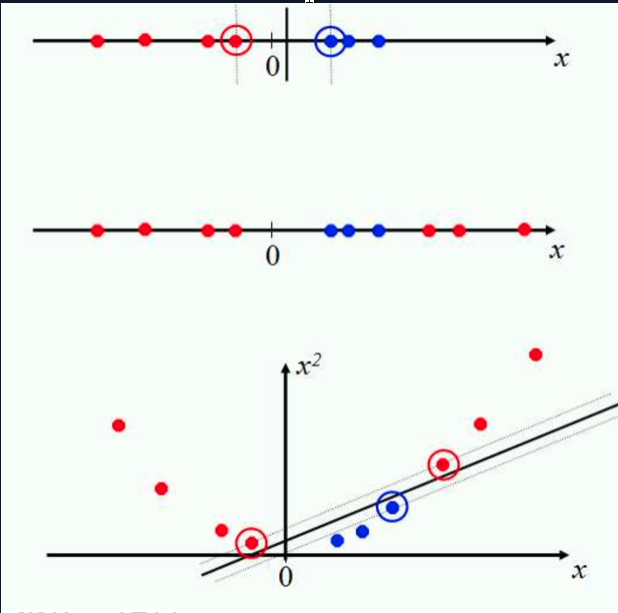
If the data cannot be separated with a straight line, SVM can use a kernel. The kernel trick changes the perspective of the feature space so that a separation becomes possible in another representation.
Mathematical form
Dual form:
L = Σᵢ αᵢ − 1/2 ΣᵢΣⱼ αᵢαⱼyᵢyⱼ(xᵢᵀxⱼ)
Kernel replacement:
xᵢᵀxⱼ → K(xᵢ, xⱼ)
Decision with kernel:
f(u) = Σᵢ αᵢyᵢK(xᵢ, u) + b
Common kernels:
Linear: K(x, z) = xᵀz
Polynomial: K(x, z) = (xᵀz + c)ᵈ
RBF: K(x, z) = exp(−γ||x − z||²)
The kernel trick works because the dual formulation depends on dot products. Replacing the dot product with a kernel function allows SVM to handle non linear separation.